Data-analyse: van beschrijvend naar verklarend
We moeten datagedreven gaan werken! Je hoort het nu overal. Maar hoe doe je dat en hoe kom je van alleen maar terugkijken naar wat er gebeurd is (beschrijven van data) naar het ook echt begrijpen waarom iets gebeurd is (verklaren/diagnosticeren van data)? Alleen dan kun je immers meer gefundeerde beslissingen nemen. In dit artikel beantwoorden we die vraag.
Het datavolwassenheidsmodel
Over de eerste stap heeft van Dam Datapartners al meerdere behulpzame artikelen gepubliceerd. Zo heeft mijn collega Rob Kerkdijk in zijn artikel datavisie en strategie het datavolwassenheidsmodel van Garnter uitgelegd. De VNG en het A&O-fonds Gemeenten hebben dit model vertaald naar het ontwikkelmodel datagedreven gemeente, te zien in onderstaande figuur.
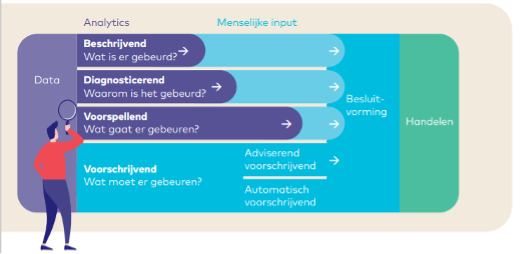
Publicatie van het VNG en A&O fonds
In de beschrijvende stap kijkt een gemeente terug naar historische gebeurtenissen. Vaak wordt er voor de analyses gebruikgemaakt van Excel. Er worden eenvoudige statistische analyses uitgevoerd om inzicht te krijgen in basiskenmerken van de data. Zoals het berekenen van gemiddelden, medianen en percentages. Vervolgens worden er patronen of trends geïdentificeerd, zoals – in het geval van het sociaal domein bijvoorbeeld – hoeveel cliënten er per jaar of per maand gestart zijn, hoeveel cliënten er zijn verwezen per soort verwijzer, de gemiddelde zorgduur per cliënt of per product(categorie) etc.
De gemeente stapt naar de verklarende fase wanneer ze de oorzaken van opmerkelijke trends wil begrijpen. Deze fase biedt diepgaandere statistische analyses en de mogelijkheid om de oorzaken van gebeurtenissen te doorgronden. Naast Excel worden meer geavanceerde analysetools gebruikt.
De voorspellende betreed je wanneer je de mogelijkheden verkent om toekomstige gebeurtenissen te voorspellen. Voorspellingen kunnen worden gedaan met geavanceerde BI-tools, en prognoses worden gecontroleerd en bijgestuurd op basis van periodieke evaluaties. Diverse methoden, zoals extrapolatie en correcties op historische data, worden toegepast.
In de voorschrijvende fase beïnvloedt de organisatie toekomstige ontwikkelingen op basis van data. Een robuuste datawarehouse-oplossing is geïmplementeerd, en gegevensbescherming is verbeterd.
Waar staan we nu: de beschrijvende fase
De meeste gemeenten weten al aardig hun weg te vinden in het beschrijven van data, oftewel ‘wat is er gebeurd’. Ze weten bijvoorbeeld hoeveel jongeren welke soort jeugdhulp ontvangen, wat de gemiddelde duur van de zorg is en de gemiddelde kosten.
Aan de hand van de beschrijvende bevindingen wordt er vanuit de praktijk naar verklaringen gezocht waarom iets is gebeurd: in een aantal gemeentes bleek bijvoorbeeld het aantal jongeren dat gebruik maakte van ondersteuning (en daarmee ook de kosten) bij de inzet van dagbesteding flink toe te nemen. Door middel van een duidingssessie met beleidsmedewerkers en uitvoerders hebben we gezocht naar mogelijke verklaringen van de beschrijvende bevindingen. Zo werd er geopperd dat dagbesteding meer ingezet wordt omdat de wachtlijsten van de daadwerkelijk benodigde hulp te lang waren terwijl er wel (snel) hulp nodig was.
Met een duidingssessie (een vorm van kwalitatief onderzoek) is de beschrijvende analyse verrijkt met deze mogelijk verklarende hypothese. Maar het op een betrouwbare manier beantwoorden van de vraag ‘waarom is dat gebeurd’ is nog lastig. Dit vereist aanvullende statistische analyses.
Om met meer zekerheid te kunnen zeggen dat de langere wachtlijsten tot meer inzet van dagbesteding hebben geleid, zijn dus verklarende analyses nodig. Hieronder leggen we je uit hoe je dat als gemeente kan doen en hoe je dus van beschrijvend naar verklarend of diagnosticerend gaat in het ontwikkelmodel datagedreven gemeente.
Correlatie en causaliteit
Even terug naar ons voorbeeld van de jeugdhulp. Er is dus mogelijk een verband tussen de toename van jongeren in dagbesteding en de lengte van de wachtlijsten voor bijvoorbeeld jeugdhulp ambulant. Met een statistische analyse kan je de vraag beantwoorden of dit een toevallig verband is: bij allebei is er een toename te zien maar hebben deze cijfers elkaar beïnvloed of is er helemaal geen verband tussen de twee toenames?
Een verband wordt in de statistiek ook wel een correlatie genoemd: er is dan een verband tussen de twee variabelen: wanneer de ene variabele verandert, verandert de andere variabele ook.
De hypothese van de uitvoerders gaat echter verder dan een correlatie, zij verwachten ook een oorzaak-gevolgrelatie: de verandering in de ene variabele veroorzaakt verandering in de andere variabele. In het genoemde voorbeeld zouden de toenemende wachtlijsten voor de juiste hulp ervoor zorgen dat er meer dagbesteding ingezet wordt, als alternatieve zorg.
Stel dat met de statistische toets blijkt dat de kans groot is dat het verband echt bestaat, dan is de volgende stap dus te onderzoeken of dit verband er is omdat het één het ander veroorzaakt, of andersom. Is dat het geval, dan spreken we van een oorzaak-gevolgrelatie, of ook wel causaliteit genoemd.
Correlatie is niet hetzelfde als causaliteit!
De veelgemaakte fout die door mensen, en ook in de media vaak wordt gemaakt is een verband verwarren met causaliteit. Zoals in de cartoon hieronder. Er kunnen namelijk ook andere verklaringen voor een verband zijn.

In het voorbeeld van het plaatje is te zien dat het de verkoop in gelijke trend toenam met het aantal geschoren hoofden. Zeer waarschijnlijk is dit gewoon een toevallig verband, maar het kan ook zijn dat er een derde factor in het spel is. Als de verkopers bijvoorbeeld een nieuw scheerapparaat moesten verkopen, en daarvoor als voorbeeld hun eigen net geschoren hoofd konden laten zien, dan kan het best zijn dat deze verkopers meer scheerapparaten hebben verkocht dan verkopers zonder kaal hoofd. Het product is dus in dit geval belangrijk om mee te nemen in je analyse. Het kan ook zijn dat degenen met een kaal hoofd toevallig betere verkoopvaardigheden hebben, daarom is het goed om ook die factor mee te nemen in de analyse. En zo zijn er nog andere factoren te bedenken.
Van beschrijvend naar verklarend: twee mogelijke routes
Er zijn twee routes te bewandelen in het verklarend analyseren van data, beide leidend naar diepgaande inzichten en betekenisvolle conclusies. Beide routes vereisen toetsing in de praktijk:
- De eerste route hebben we eigenlijk al beschreven: de data worden beschreven met eenvoudige statistische analyses, deze bevindingen worden besproken met uitvoerders en beleidsmedewerkers en samen worden opvallende bevindingen geduid en verklarende hypothesen opgesteld. Tot zover bevinden we ons nog in de beschrijvende fase. De stap naar verklarend wordt gemaakt wanneer de hypothese wordt getoetst met geavanceerde statistische berekeningen, in de eerste plaats door te kijken of er sprake is van een correlatie en daarna of er sprake is van een oorzaak-gevolgrelatie (causaliteit). Na deze berekeningen worden de bevindingen weer teruggekoppeld, besproken en getoetst met de uitvoerders en de beleidsmedewerkers.
- Een andere route slaat eigenlijk de eerste toetsing over. De data worden door de ervaren data-analist direct beschreven en opvallendheden worden meteen verklarend geanalyseerd. Het proces is intensiever, waarbij de data-analist snel en vakkundig hypotheses formuleert, deze toetst aan de werkelijkheid waarna hij of zij terugkomt met bevindingen die direct impact hebben op de praktijk.
Uiteindelijk zijn beide routes een cyclisch avontuur. De routes worden herhaaldelijk betreden in een iteratief proces. De data worden geanalyseerd, geïnterpreteerd in de context van de praktijk, hypotheses worden geformuleerd en getoetst, en dit alles wordt vervolgens opnieuw besproken met de uitvoerders in de praktijk. Een proces van inzicht en actie, waarbij elke herhaling nieuwe diepten onthult en de weg effent voor datagedreven besluitvorming.
Op deze manier wordt de reis van beschrijvend naar verklarend niet alleen een analytische onderneming, maar ook een dynamisch samenspel tussen de wereld van data en de realiteit van beleidsvorming.
Ingrediënten
Nu we hebben besproken hoe je de route kunt kiezen tussen beschrijvende en verklarende analyses, is het goed eens te kijken naar de essentiële ingrediënten die nodig zijn voor een succesvolle verklarende analyse. Hieronder vind je de cruciale factoren die een rol spelen in het verklarend analyseren van data
- Data van de variabelen waar je een verband verwacht
Zorg ervoor dat de data die je verzamelt van hoge kwaliteit zijn. Onnauwkeurige of onbetrouwbare gegevens kunnen de resultaten van je analyse vertroebelen.
- Inzicht in variabelen die ook van invloed kunnen zijn op het verband of één van de variabelen
Het is goed om te onderzoeken, bijvoorbeeld aan de hand van literatuuronderzoek, welke andere variabelen allemaal van invloed kunnen zijn op een bepaalde variabele of het verband dat je denkt te zien. Deze beïnvloedende verbanden noemen we confounders. De toename in dagbesteding kan bijvoorbeeld ook komen door een uitbreiding van het aanbod aan dagbesteding, waardoor dit sneller en vaker wordt ingezet. Daarnaast kunnen financiële prikkels, subsidies of wijzigingen in financieringsmodellen van invloed zijn op de keuze voor dagbesteding als een direct beschikbare optie, zelfs als er andere vormen van jeugdhulp nodig zijn. We zien ook dat de maatschappij verandert, ouders vaker allebei werken en de stress toeneemt, waardoor er mogelijk een grotere behoefte is aan deze vorm van ondersteuning.
- Data van die alternatieve variabelen
Confounders kunnen de resultaten vertekenen als ze niet worden meegenomen. De confounders probeer je daarom zoveel mogelijk te meten en constant in de statistische analyse te houden. Je wilt namelijk weten of er een verband is tussen de toename in wachtlijsten en de toename in jongeren in dagbesteding, ook als je rekening houdt met andere invloeden.
- Een representatieve steekproef
Deze factor kan gecompliceerd zijn, met name voor kleinere gemeenten. Zo moet de steekproef groot genoeg zijn (de groep waarover je de berekening doet), het liefst groter dan 30 personen. Bij kleinere steekproeven is de kans groter dat de uitkomst niet betrouwbaar en representatief is. Meer uitleg over steekproeven vind je in ons eerdere artikel.
- Een causale volgorde
Voor causaal onderzoek is het nodig dat er een logische volgorde is, de variabele die als oorzaak wordt verwacht moet voorafgaan in de tijd aan de variabele waar het gevolg of het effect op wordt verwacht.
- Een data-analist
Om de verklarende analyses te kunnen uitvoeren.
- Statistisch geavanceerd programma
Tot slot is er een statistisch programma nodig voor de diagnosticerende variabelen, zoals R, Python of SPSS. Er moeten namelijk statistische berekeningen worden gedaan die niet zo makkelijk in bijv. Excel zijn uit te voeren. In onderstaande tabel zijn de voor- en nadelen van de drie veel voorkomende tools beschreven.
| SPSS | Python | R |
| Gebruiksvriendelijke grafische interface, vraagt minder programmeerkennis | Een algemene programmeertaal. Je hebt veel meer flexibiliteit om aangepaste analyses, data cleaning, en complexe workflows te maken. | Open-source programmeertaal, wat betekent dat je vrijwel elke gewenste analyse kunt uitvoeren en aanpassen door code te schrijven. Hierdoor is R krachtiger en flexibeler voor complexe analyses en onderzoeksvragen. |
| Heeft een snellere ontwikkelingstijd bij eenvoudige analyses | Python heeft krachtige libraries zoals NumPy, pandas, matplotlib en scikit-learn die veel functionaliteit bieden voor data-analyse, statistiek en machine learning. | Aangezien analyses in R worden uitgevoerd via scripts, is het gemakkelijk om je werk reproduceerbaar te maken. Dit is belangrijk voor wetenschappelijk onderzoek en rapportage. |
| Het biedt een uitgebreide reeks van vooraf gebouwde statistische analyses en datavisualisaties | Een grote en actieve community, wat betekent dat je gemakkelijk hulp kunt vinden, of het nu gaat om programmeervragen, analytische uitdagingen of het delen van kennis | R heeft een actieve en groeiende gemeenschap van gebruikers en ontwikkelaars, waardoor er een enorm aantal pakketten beschikbaar is voor diverse analyses en visualisaties. Dit maakt het gemakkelijk om geavanceerde technieken toe te passen. |
| SPSS is niet gratis en heeft daardoor hogere kosten in het gebruik ervan. | Het is gratis en je hebt volledige controle over de tools en technologieën die je gebruikt | R is gratis te gebruiken en te verspreiden, wat een kosteneffectieve oplossing kan zijn voor individuen, onderzoekers en organisaties met beperkte budgetten. |
Python heeft een rijk aanbod van bibliotheken die specifiek gericht zijn op wetenschappelijke en statistische analyse. Hierdoor kun je aangepaste analyses uitvoeren en meer geavanceerde methoden toepassen dan wat standaard in SPSS wordt aangeboden. Bovendien kun je met Python en R makkelijker analyses combineren met andere taken, zoals data cleaning, visualisatie en machine learning. Over het algemeen is SPSS handig voor snelle en eenvoudige analyses zonder programmeerervaring, Python is veelzijdig en geschikt voor complexe gegevensverwerking en automatisering, en R is sterk op het gebied van geavanceerde statistische analyses en wetenschappelijk onderzoek. Welke tool gekozen wordt hangt dus voornamelijk af van de expertise die in huis is.
Na de analyse: interpreteren van de uitkomst en duiden in de praktijk
We gaan in dit artikel niet in op de uitvoering van de analyses en welk soort statistische analyses er zijn om correlatie en causaliteit aan te tonen. Om in het verklarende niveau van datavolwassenheid te komen als gemeente is het een vereiste om de expertise in huis te hebben (of te halen) om deze analyses te kunnen uit te voeren, waarbij uitbesteden ook een optie is.
Wanneer er een verband of zelfs een oorzaak-gevolgrelatie is aangetoond, is het nog altijd belangrijk om deze in de praktijk te toetsen. Je wilt weten of beleidsmedewerkers en uitvoeringsorganisaties en -medewerkers deze uitkomst(en) herkennen. Wat betekent deze uitkomst en wat zijn de mogelijkheden om deze uitkomst te gebruiken om de praktijk te verbeteren? Stel dat bijvoorbeeld uit de analyse blijkt dat er inderdaad een oorzaak-gevolgrelatie is tussen de lengte van de wachtlijsten en de inzet van dagbesteding, dan is het nog altijd de vraag wat aan de hand hiervan de mogelijkheden zijn om de lengte van de wachtlijsten in te perken. Hoe zien uitvoerders en beleidsmedewerkers dit? Wat zijn mogelijkheden om de wachtlijsten in te korten? Wat zijn belemmeringen in de praktijk? Dit is dan ook een essentiële en niet te missen stap, voordat wordt overgegaan op eventuele beleidsveranderingen.
Tot slot
In de overgang van beschrijvende naar verklarende data-analyse is een cruciale stap om van datagedreven beschrijvingen naar daadwerkelijke verklaringen te komen. Hoewel veel gemeenten bedreven zijn in het beschrijven van data, blijkt het verklaren van ‘waarom’ uitdagender. We hebben in dit artikel besproken hoe de stap van beschrijvend naar verklarend kan worden gezet. Door correlatie en causaliteit te analyseren, zoals geïllustreerd met een voorbeeld uit de jeugdhulp, kunnen gemeenten inzicht krijgen in de onderliggende oorzaken van trends. We benadrukken echter ook het belang van kritische reflectie op mogelijke alternatieve verklaringen en het praktisch toetsen van bevindingen, voordat beleidsveranderingen worden overwogen. De reis van beschrijvende naar verklarende analyses vereist dus niet alleen statistische expertise maar ook een nauwe samenwerking tussen data-analisten, beleidsmedewerkers, en uitvoerders om tot zinvolle inzichten te komen die leiden tot verbeteringen in de praktijk. Ben je al helemaal thuis in de verklarende analyses en wil je juist de stap naar voorspellend of voorschrijvend maken? Houd dan onze kennisbank in de gaten; binnenkort verschijnt deel drie van mijn onderzoeksreeks over vragenlijsten opstellen in de vorm van een whitepaper.
Heb je vragen naar aanleiding van dit artikel nog vragen of wil je meer weten over hoe van Dam Datapartners jou kan helpen de stap van beschrijvende data-analyse naar verklarende data-analyse te maken? Neem dan gerust contact met mij op via leonie.lubbersen@vandamdatapartners.nl






